Context
The problem
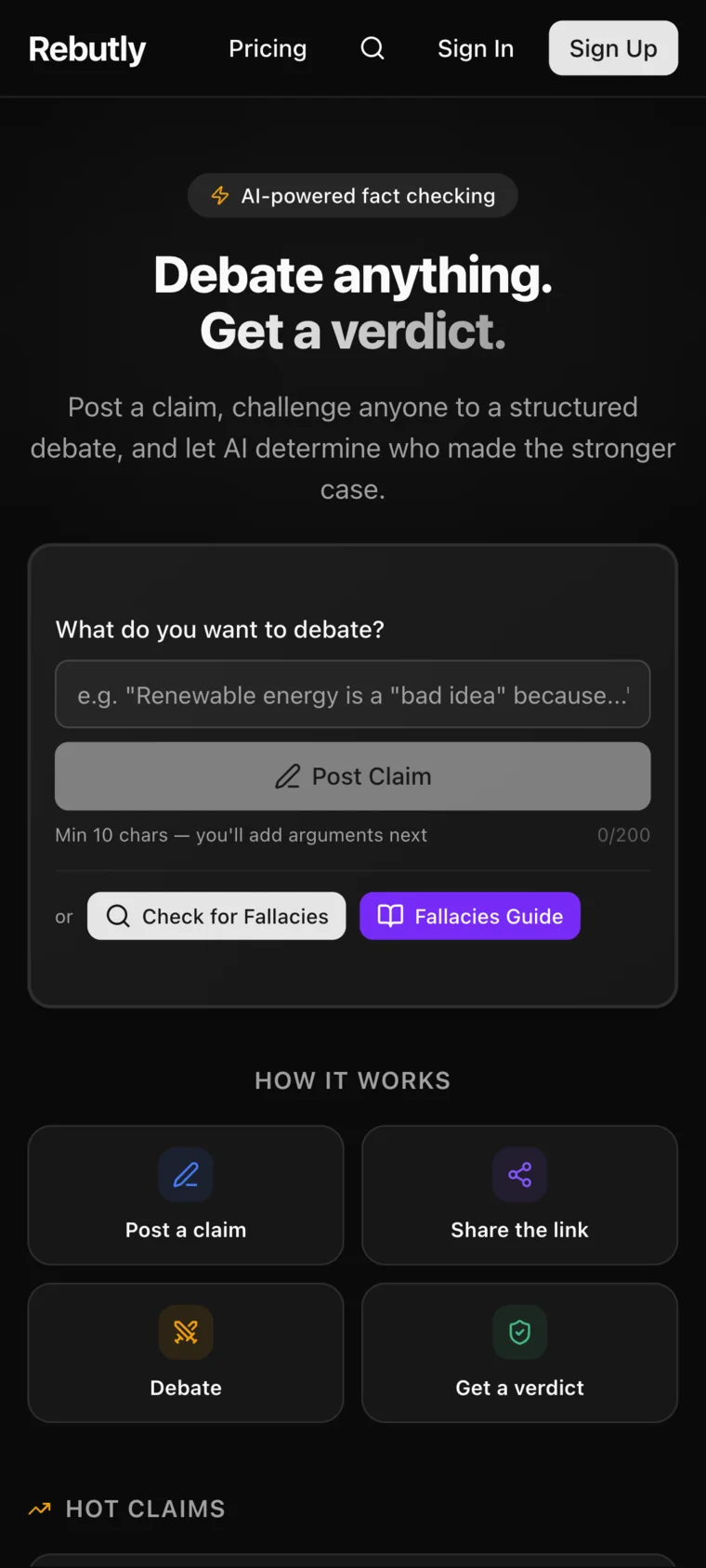
Online arguments have no referee. Rebutly scores debate claims and rebuttals with an LLM — but raw LLM output is unreliable as application data: free-text scores drift, formats break, and a UI can't be built on top of prose. The hard problem wasn't prompting; it was making model output trustworthy enough to render, rank, and persist — at a unit cost that survives a free tier.
Ownership
My role
Solo build — product, scoring pipeline, realtime layer, payments, and frontend.
Solution
Approach
Schema-first LLM pipeline
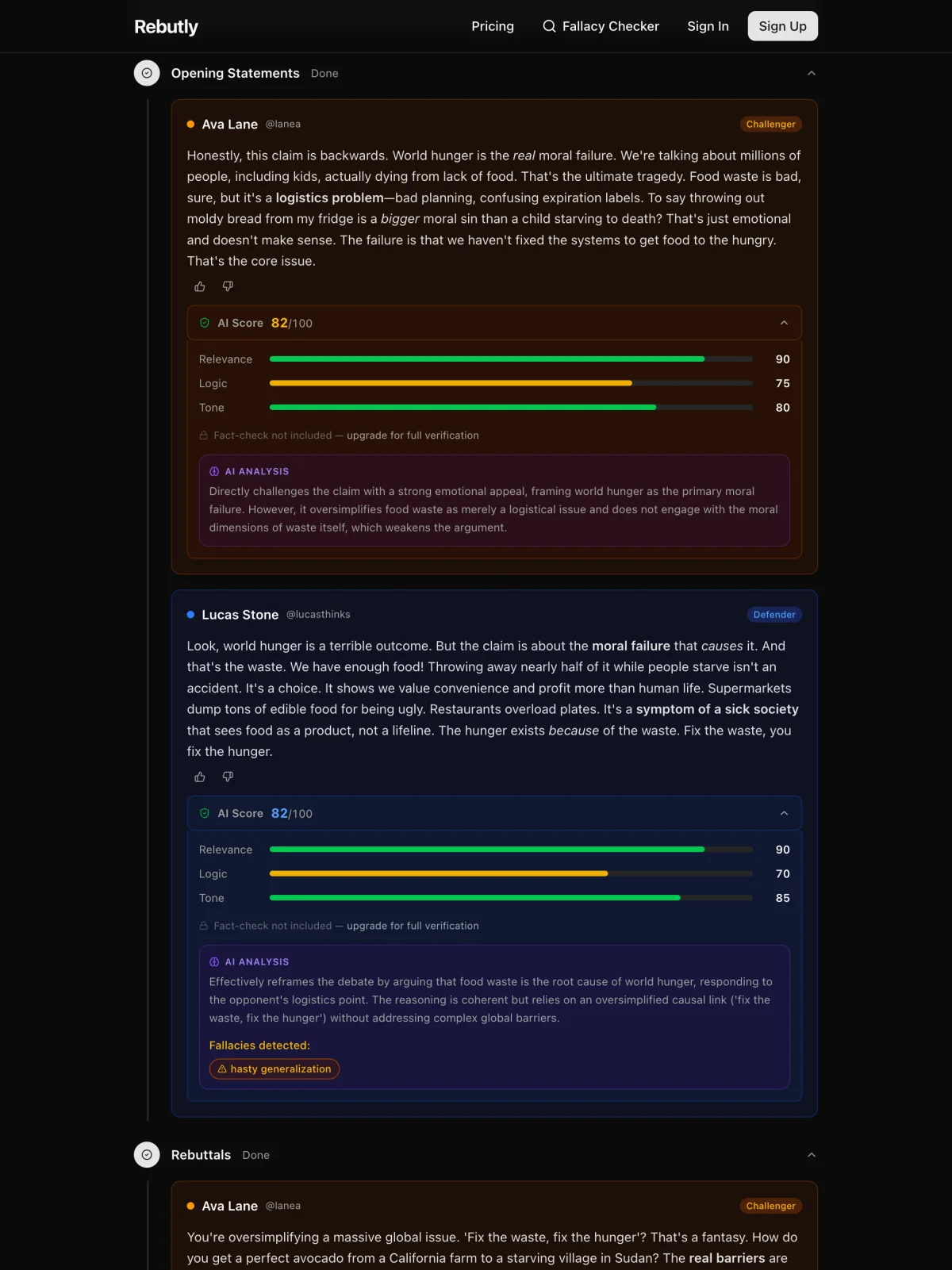
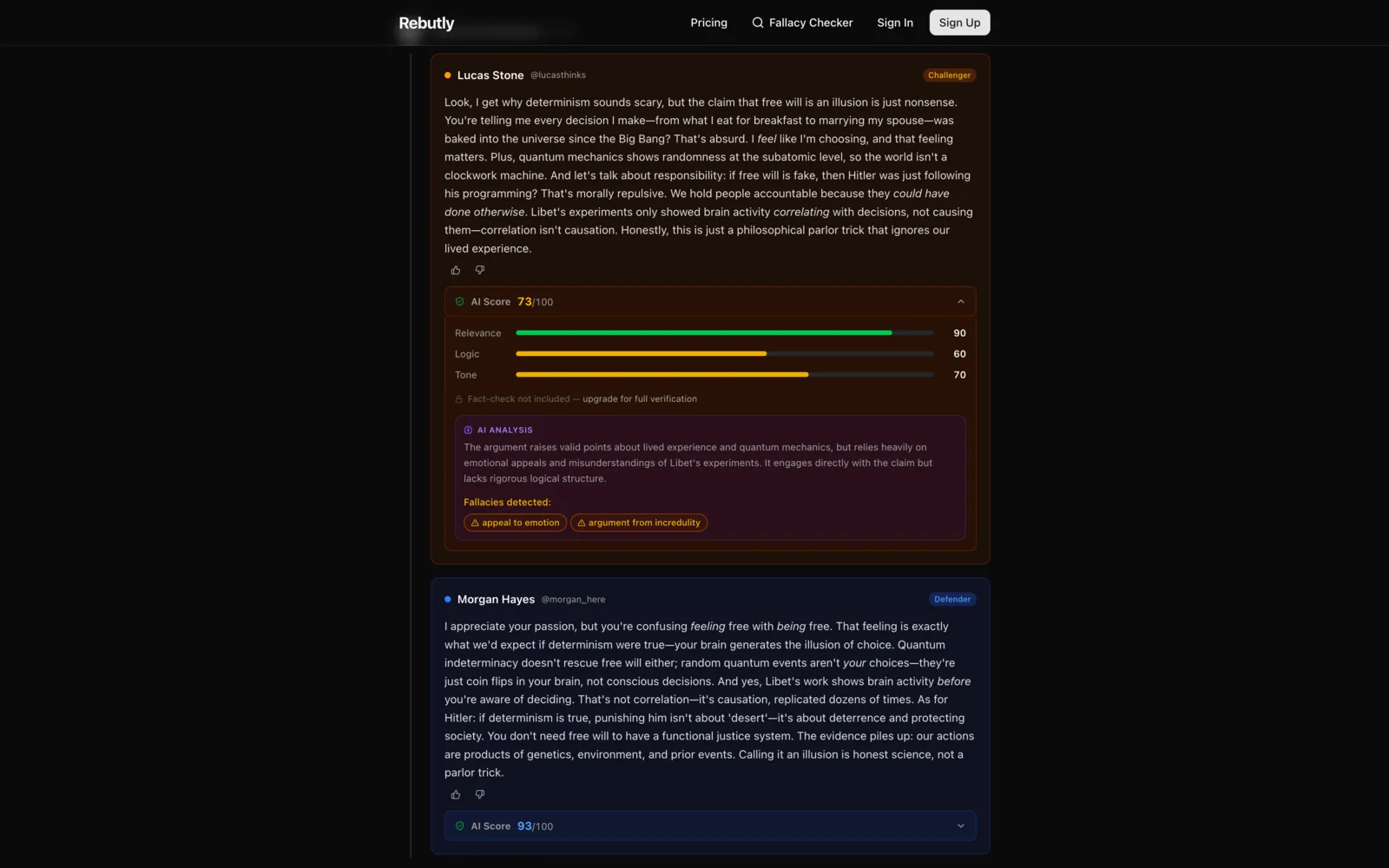
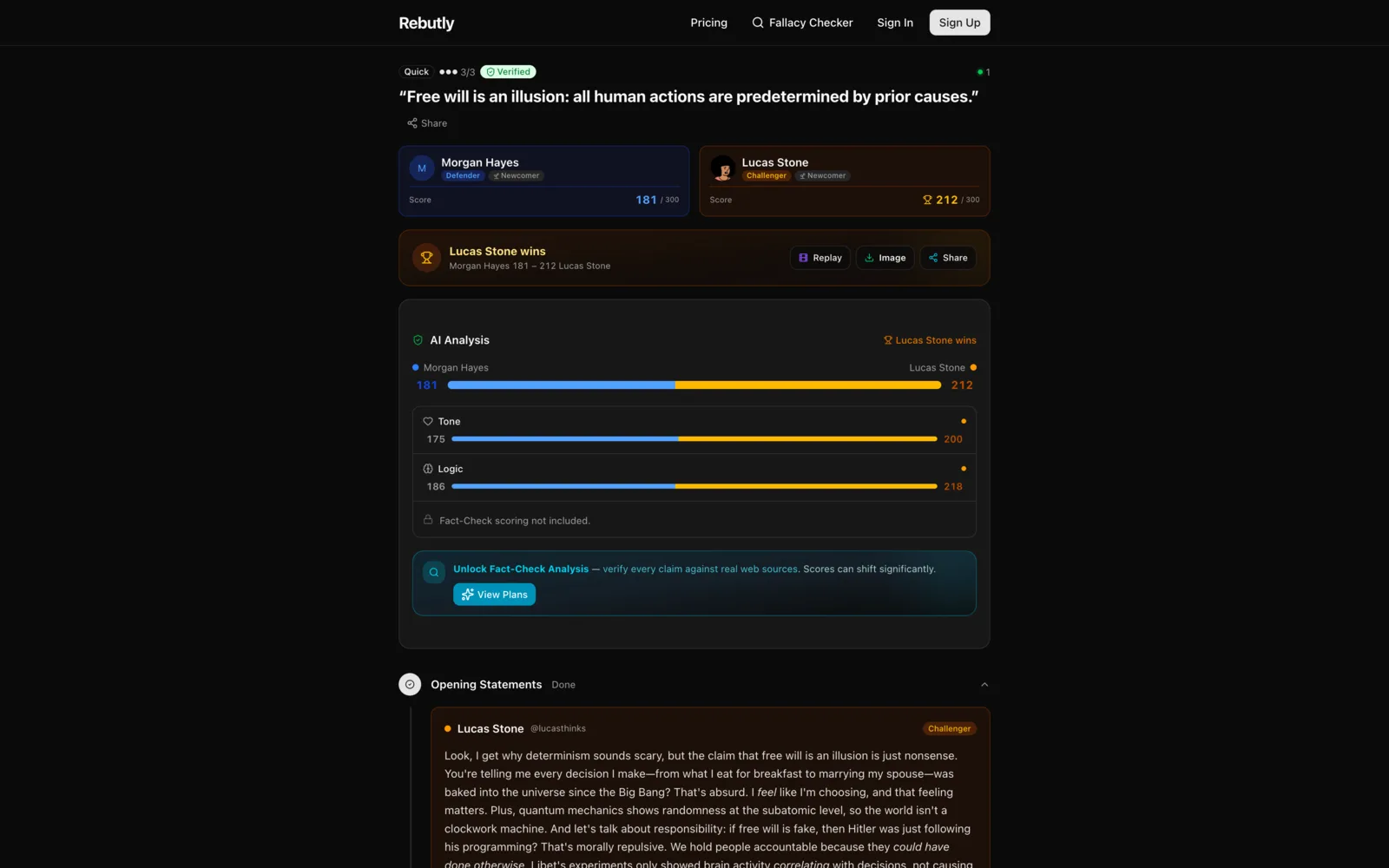
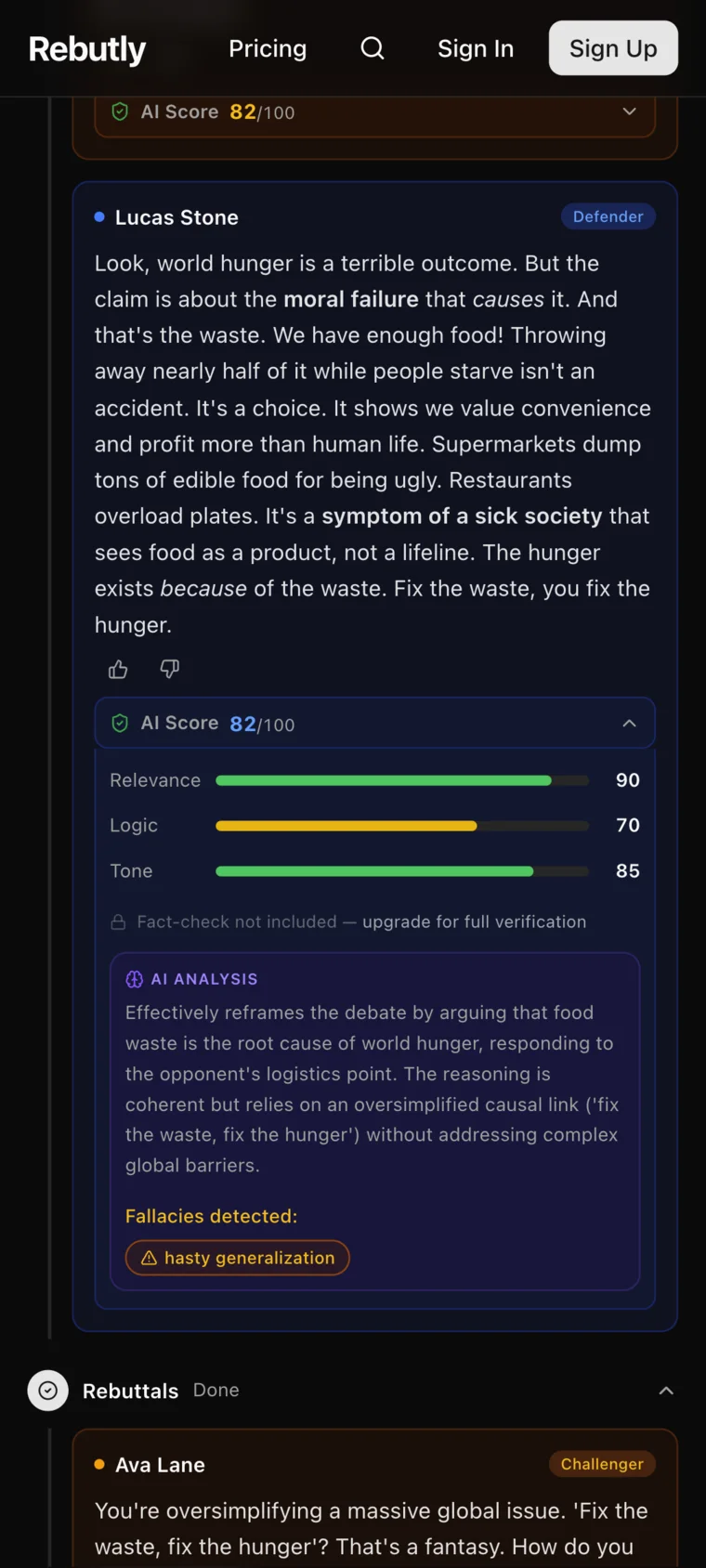
Every model call is contracted by a Zod schema: scores are clamped 0–100 with defaults, responses must parse as pure JSON, and a validation failure throws — which hands the call to a job queue that retries with exponential backoff. User content is embedded in XML-structured prompts with angle brackets sanitized to fullwidth Unicode, so debate text can't inject instructions. The application layer only ever sees typed, validated scoring objects — never raw model text.
Two models, three verification tiers
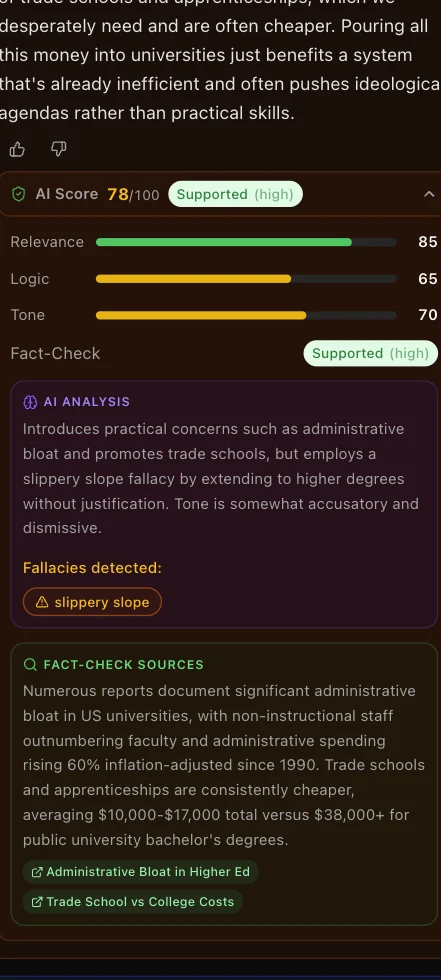
DeepSeek handles scoring and claim extraction — with thinking mode switched on for reasoning calls and off for generation, because they price differently — and Perplexity Sonar fact-checks extracted claims against live web sources, returning a verdict (supported / mixed / disputed / unverifiable), confidence, and citations. Debaters choose a verification tier — tone, logic, or full fact-check — and a completed verification at a higher tier is reused instead of re-billed.
Scoring that changes incentives
Each turn gets tone, logic, and relevance scores plus detected logical fallacies — relevance explicitly penalizes statements that are factually true but dodge the opponent's argument. Ratings use a non-zero-sum ELO with split K-factors across tone, logic, and fact dimensions: both debaters can gain rating if both argue well, and both can lose it for a mud fight. Winning multiplies positive gains by 1.5× — it rewards quality first, victory second.
Cost engineering for a free tier
An entire debate is scored in one batched model call — every turn in a single request with the token budget scaled to turn count — instead of one call per turn. A daily budget circuit-breaker hard-stops AI spend at a configured cap, and every call lands in a usage ledger with per-provider token and cost breakdowns down to fractions of a cent. A full multi-model verification costs about a cent.
System
Architecture
A Turborepo monorepo: Next.js frontend, Hono API, shared Zod packages, PostgreSQL with Drizzle, and a PostgreSQL-backed job queue for verification work. Self-hosted LiveKit powers live audio debates, with data channels pushing score updates to spectators in realtime.
- Zod schemas as the single contract between model and application — validation failure triggers queued retry
- Batched scoring: all debate turns evaluated in one model call
- Per-call AI usage ledger: provider, model, cached/reasoning/citation tokens, cost to 6 decimals
- Daily AI budget circuit-breaker with in-memory caching
- Live audio debates over self-hosted LiveKit with realtime score pushes
- Paddle subscriptions with per-tier usage caps
Results
Outcomes
100%
of rendered scores schema-validated
1 call
scores an entire debate, every turn batched
~1¢
for a full two-model fact-checked verification
0
free-text model output reaching the UI
- Live at rebutly.com.
- The schema-first pattern generalizes to any LLM-backed product — it's the same discipline I bring to client AI work.
- Cost ledger + circuit breaker means the free tier can't bankrupt the platform.
Contact
Let's build something great.
Open to Senior, Staff, and Founding Engineer roles — and select freelance engagements. Reply within 24 hours, CET timezone.